| Comparative linguistics - Trees |
|---|
|
Offline comment by: Harald on February 7, 2013, 11:00
I make the point about the system, but I don't understand why you skip some clear sound correspondences like S <-> T and C <-> T. This missing link is very obvious in the English to German detail sheet.
|
|
Posted by: Vincent on February 14, 2013, 21:00
Yes, you are right. S <-> T is part of the present rules. I just had a mistake in my XML file at the time you tested - it is corrected now. Re. C <-> T: this is part of sound correspondences I have dropped, because they caused a big
"statistical noise" - which means it generated too much cognates between remote languages which were due to chance. But to be honest, this was before I adapted my algorithm to a pattern, where consonant matches only count if they appear in the same order
within the words. I have tested the tree with C <-> T as a valid related consonant match - and it doesn't produce more "statistical noise". Now let's play farther and make following hypothesis: we don't work with consonants for coding the lexical morphemes, but with numbers which represent consonant clusters. It means, we gather consonants which are more or less remotely related within one cluster like this:

Here is the detail sheet for English to German (better proximity than in the classical sound correspondence tree by the way!) 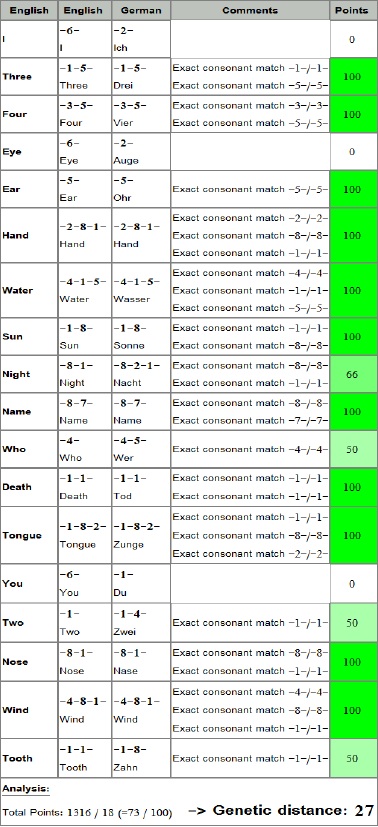 Harald, thank you for this discussion - it is good to try even simpler sound correpondance patterns and it seems it even improve the results. I will try more on these tracks. |

Forum » Broad sound correspondence hypothesis